索引
介紹
MySQL 排好序的數據結構,以某種方式引用數據,實現高級查找方法。大廠 95% 場景使用單表查詢,索引效率高。
- 二叉樹(自增數據對索引存儲傾斜)
- 紅黑樹(層級高,數的高度太高)
- Hash 表(不支持範圍查詢、無法利用索引做排序操作)
- B-Tree(一顆最大度數為5,表示節點儲存4個Key,5個指針,一個節點空間16KB)
B-Tree(節點存儲的Key較少)
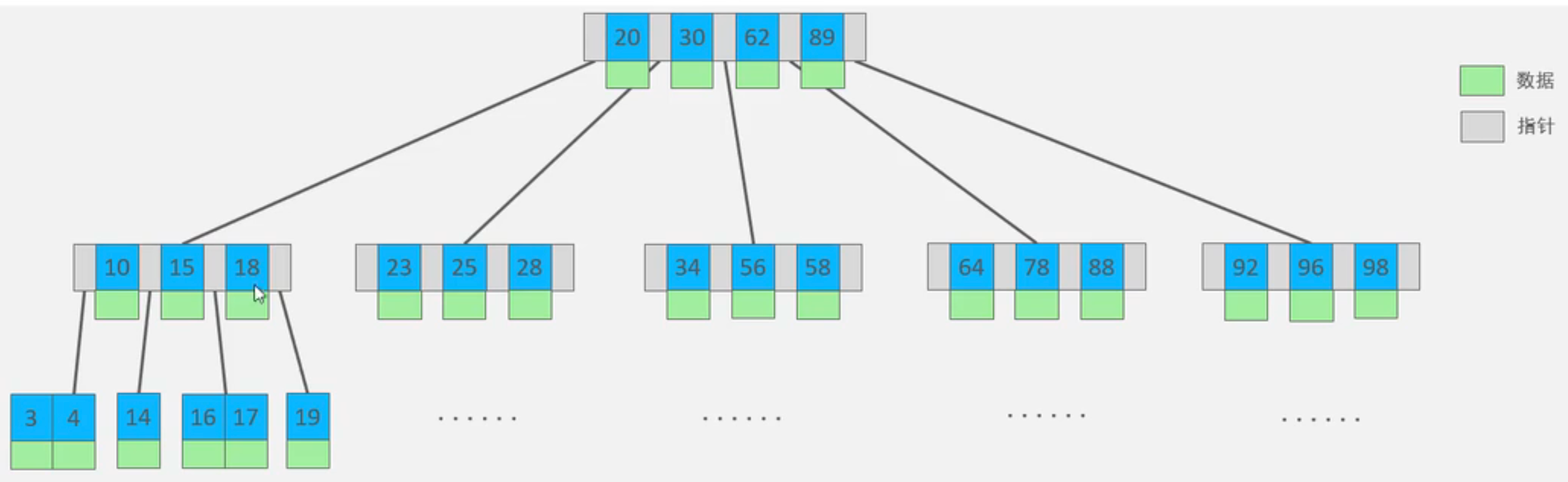
B+Tree(節點存儲的Key較多)
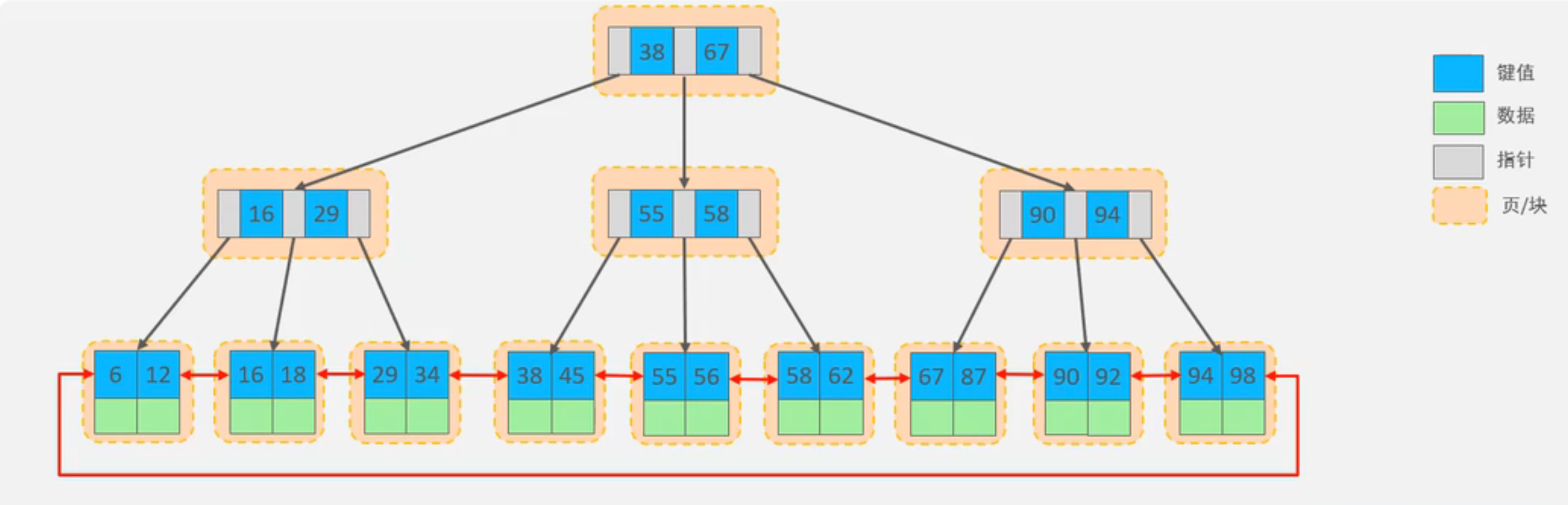
優點:
- 提高數據查詢效率
- 通過索引進行排序,降低數據排序成本,降低 CPU 消耗
缺點:
- 佔用儲存空間
- 降低更新表效率
索引結構圖
連結層:最上層是客戶端和鏈接服務,主要完成連結處理、授權認證及相關安全方案,並且驗證每個客戶端接入驗證操作權限。 服務層:第二層架構完成核心服務功能,如 SQL 接口、完成緩存查詢、SQL 分析、SQL 優化、部分內置函數的執行。 引擎層:負責數據存儲和提取,通過 API 和存儲引擎進行通訊。 存儲層:數據存儲在文件系統上,並完成與存儲引擎的交互
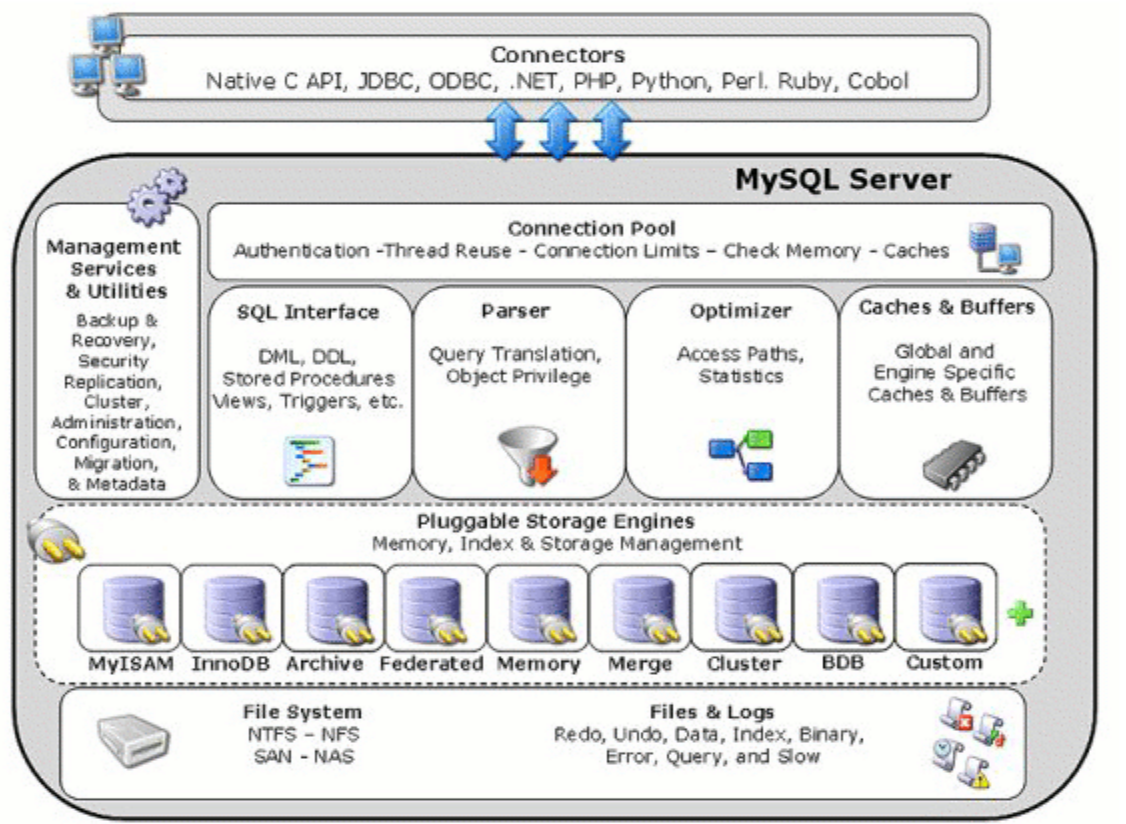
索引分類
- 主鍵索引:表中主鍵創建的索引,自動創建,只能一個,PRIMARY
- 唯一索引:避免同一表中某數據列中的值重複,可以多個,UNIQUE
- 常規索引:快速定位特定數據,可以多個
- 全文索引:全文索引查找的是文本中的關鍵詞,而不是比較索引的值,FULLTEXT
- 聚集索引:索引和行數據放在一起,必須有且只有一個
- 二級索引:索引和行數據分開,葉子節點存儲的是主鍵,可以有多個
思考:InnoDB主鍵索引的B+Tree高度為多高呢? 假設:一行數據大小1KB,一頁中可以存儲16行數據,指針佔用 6 bytes,主鍵 8 bytes,高度為 2 算出節點 1170,索引數量 117016=18736;同理高度為 3 索引數量 11701170*16=21939856
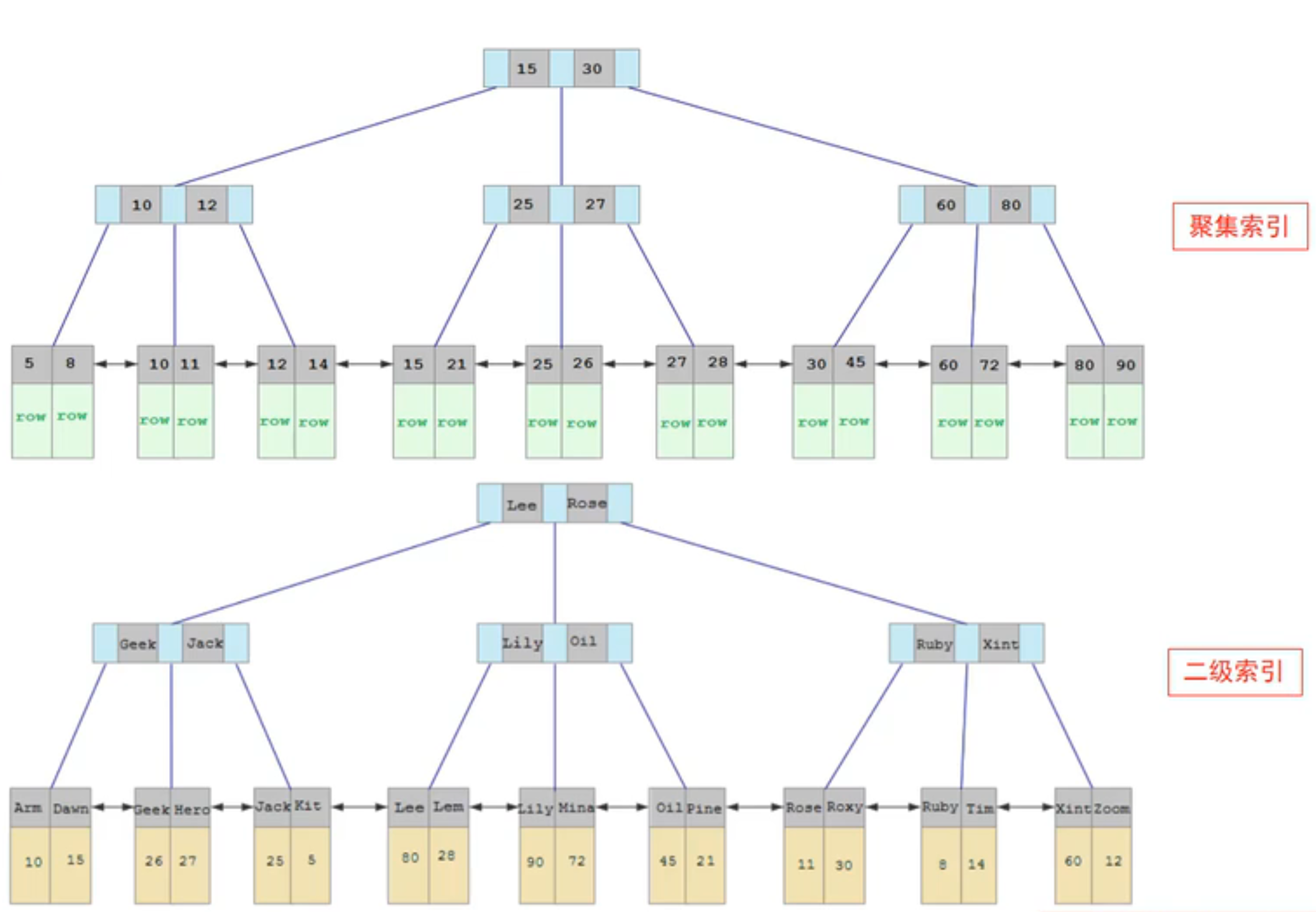
索引語法
創建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (index_col_name...);
查看索引
SHOW INDEX FROM table_name;
刪除索引
DROP INDEX index_name ON table_name;
SQL性能分析
SQL執行頻率
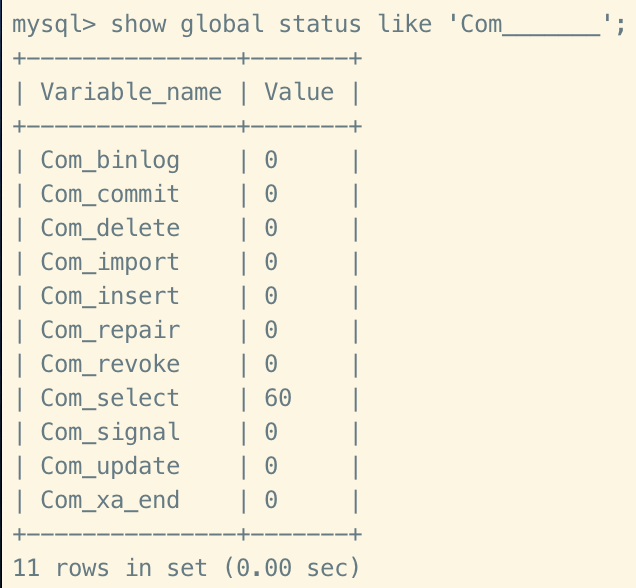
MySQL 客戶端連接成功後,通過 show [session|global] status 命令查看服務器狀態訊息,查看 INSETT、UPDATE、DELETE、SELECT的訪問頻率。
SHOW GLOBAL STATUS LIKE `Com_______`; // 7個底線
慢查詢日誌
慢查詢日誌記錄所有執行時間超過指定參數(long_query_time,單位:秒,默認10秒)的所有SQL語句日誌。MySQL 的慢查詢日誌默認沒有開啟,需要在 MySQL 的配置文件(/etc/my.conf)配置訊息。慢查詢日誌位置(/var/lib/mysql/localhost-slow.log)。
show variables like 'slow_query_log'; // 查詢慢查詢配置
配置文件增加以下配置。
#開啟慢查詢日誌
slow_query_log=1
#設置慢查詢日誌時間為2秒,SQL語句執行時間超過2秒,就會視為慢查詢作記錄
long_query_time=2
profile 詳情
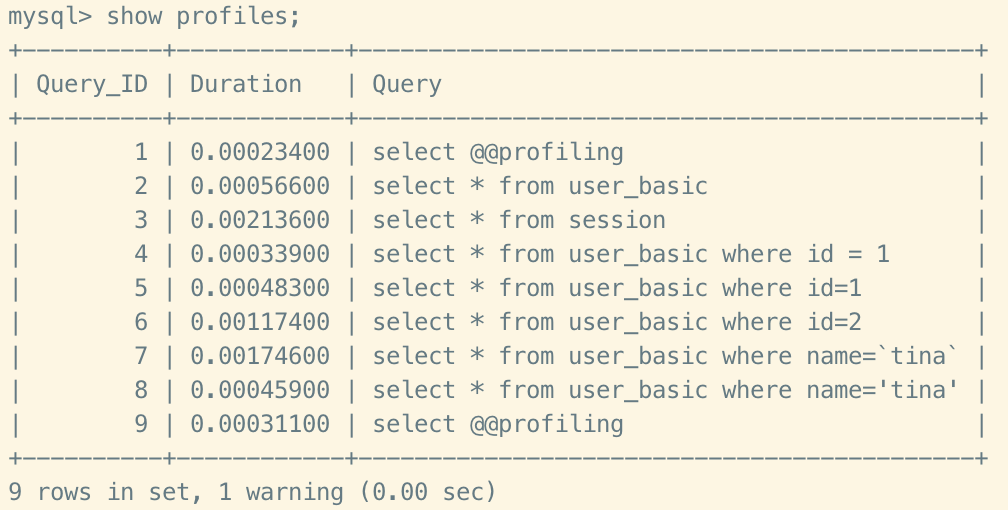
show profiles 能夠在做 SQL 優化時幫助我們了解時間耗費到哪裡去了。通過 have_profiling 參數,能夠看到當前 MySQL 是否支持 profile 操作。
select @@have_profiling;
SET profiling=1;
執行一系列業務 SQL 操作,然後通過以下指令查看指令的執行時間。
#查看每一條SQL的耗時基本情況
show profiles;
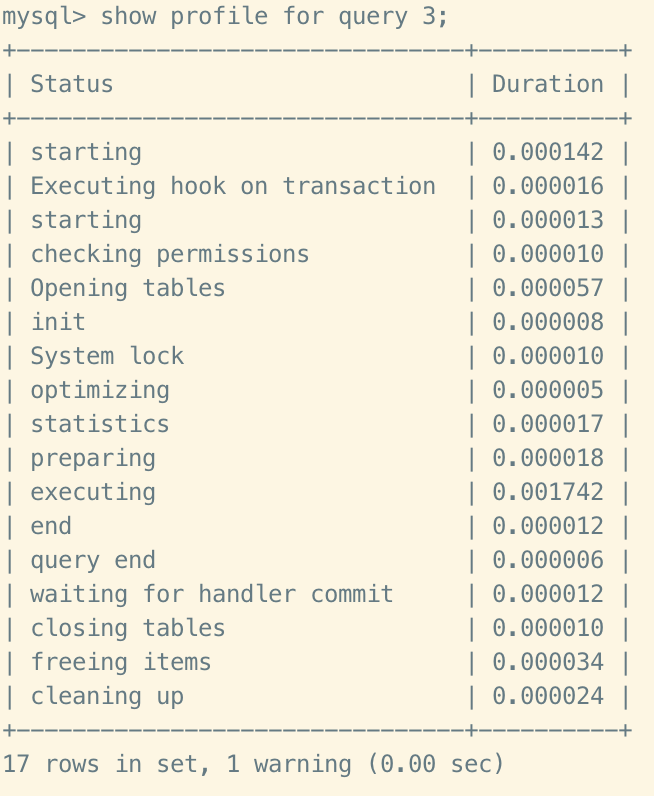
#查看指定query_id的SQL語句各個階段耗時情況
show profile for query query_id
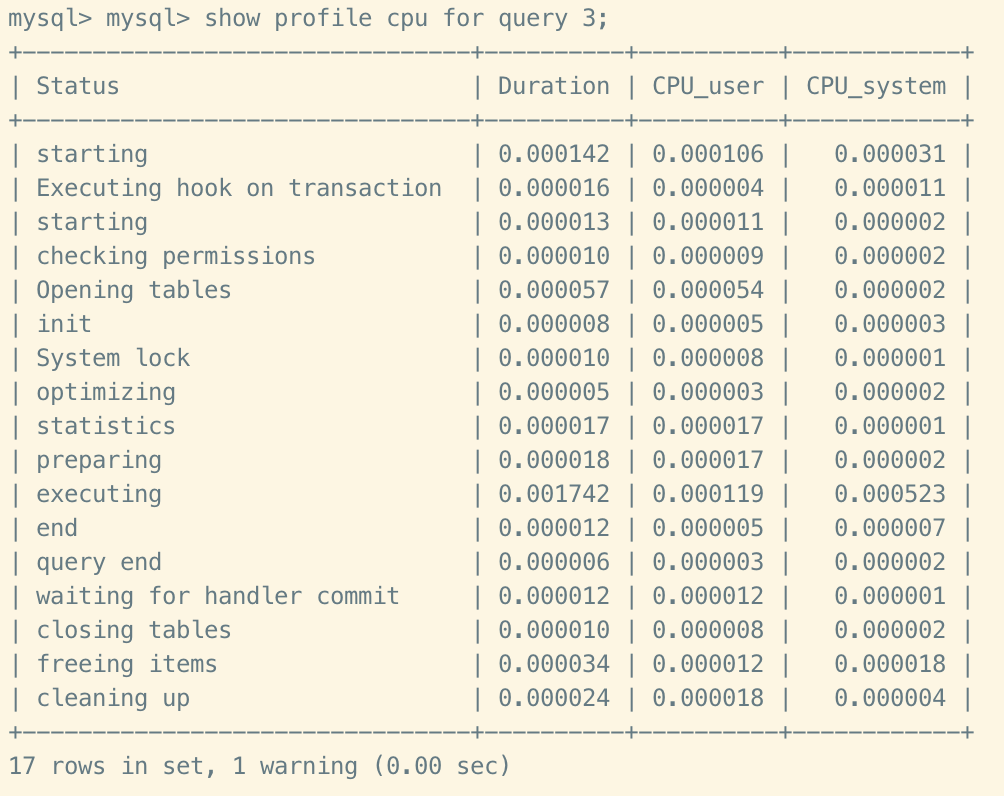
#查看指定query_id的SQL語句CPU使用情況
show profile cpu for query query_id;
explain執行計畫
EXPLAIN 或者 DESC 命令獲取 MYSQL 如何執行 SELECT 語句訊息,包括在 SELECT 語句執行過程中表如何連接的順序。
各字段含義: id:select查詢的序列號,表示查詢中執行 select 子句或者操作表的順序(id相同,執行順序上到下;id不同,值越大先執行) select_type:SIMPLE(簡單表,即不用表連結或者子查詢)、PRIMARY(主查詢,即外層查詢)、UNION(UNION中的第二個或者後面的查詢語句)、SUBQUERY(SELECT / WHERE之後包含了子查詢) type:表示連接類型,性能有好到差的連接類型為NULL、system、const、eq_ref、ref、range、index、all。 possible_key:顯示可能應用在這張表的索引,一個或多個。 Key:實際使用的索引,如果為NULL,表示沒有使用索引。 Key_len:表示索引中使用的字節數,該值為索引字段最大可能長度,並非實際使用長度,在不損失精確性的前提下,長度約短越好。 rows:MySQL認為必須要執行查詢的行數,在innodb引擎的表中,是一個估計值。 filterd:表示返回結果的行數占需要讀取行數的百分比,filterd的值越大越好。
explain select 字段列表 from 表名 where 條件;

索引使用規則
驗證索引效率:先執行查詢看效果,再建立索引,比較前後查詢效率 最左前綴法則:針對聯合索引,從索引最左列開始,並且不跳過索引中的列,如果跳過則後面字段索引失效 範圍查詢:聯合索引中,出現範圍查詢(<,>),範圍查詢右側的列索引失效 索引列運算:索引列上進行運算操作,索引將失效 字符串不加引號:字符串類型索引不加引號,索引失效 模糊查詢:尾部模糊匹配,索引不失效;若是頭部模糊匹配,索引失效 or 連接的條件:用 or 分開的條件,如果 or 前的條件中的列有索引,而後面的列沒有索引,那麼索引都會失效 數據分佈影響:MySQL評估使用索引比全表慢,則不會使用索引(匹配數據量接近全表數據量則不使用索引) 索引提示:SQL 語句中加入人為的提示達到優化操作的目的,use index、ignore index、force index 覆蓋索引:盡量使用覆蓋索引減少 select *;若查詢的列不是索引,需要回表查詢滿足查詢的數據。
# explain SQL 語句,EXTRA 資訊
using index condition: 查找使用了索引,但是需要回表查詢數據
using where; using index: 查找使用了索引,但是需要的數據都在索引列中能找到,所以不需要回表查詢
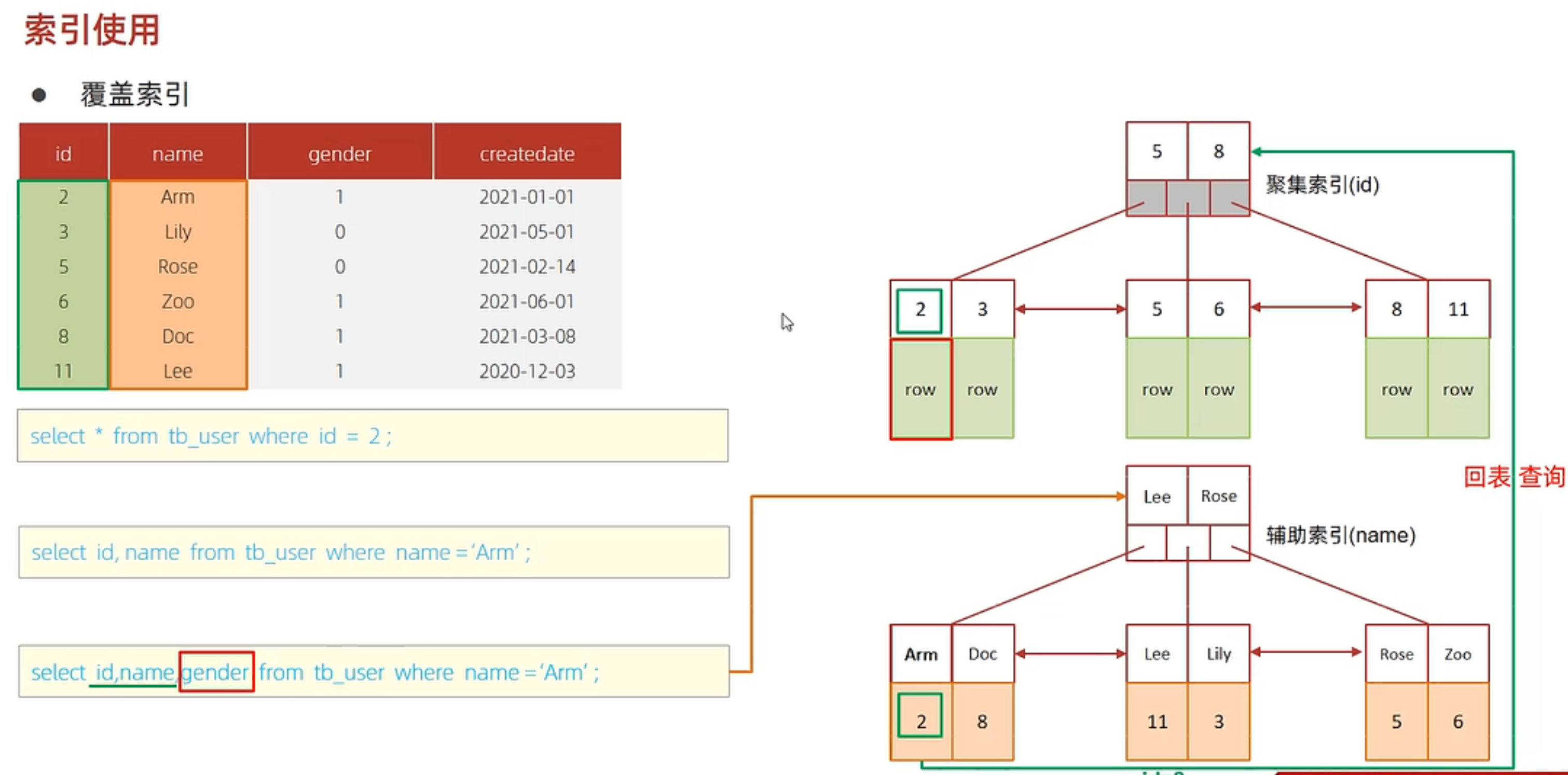
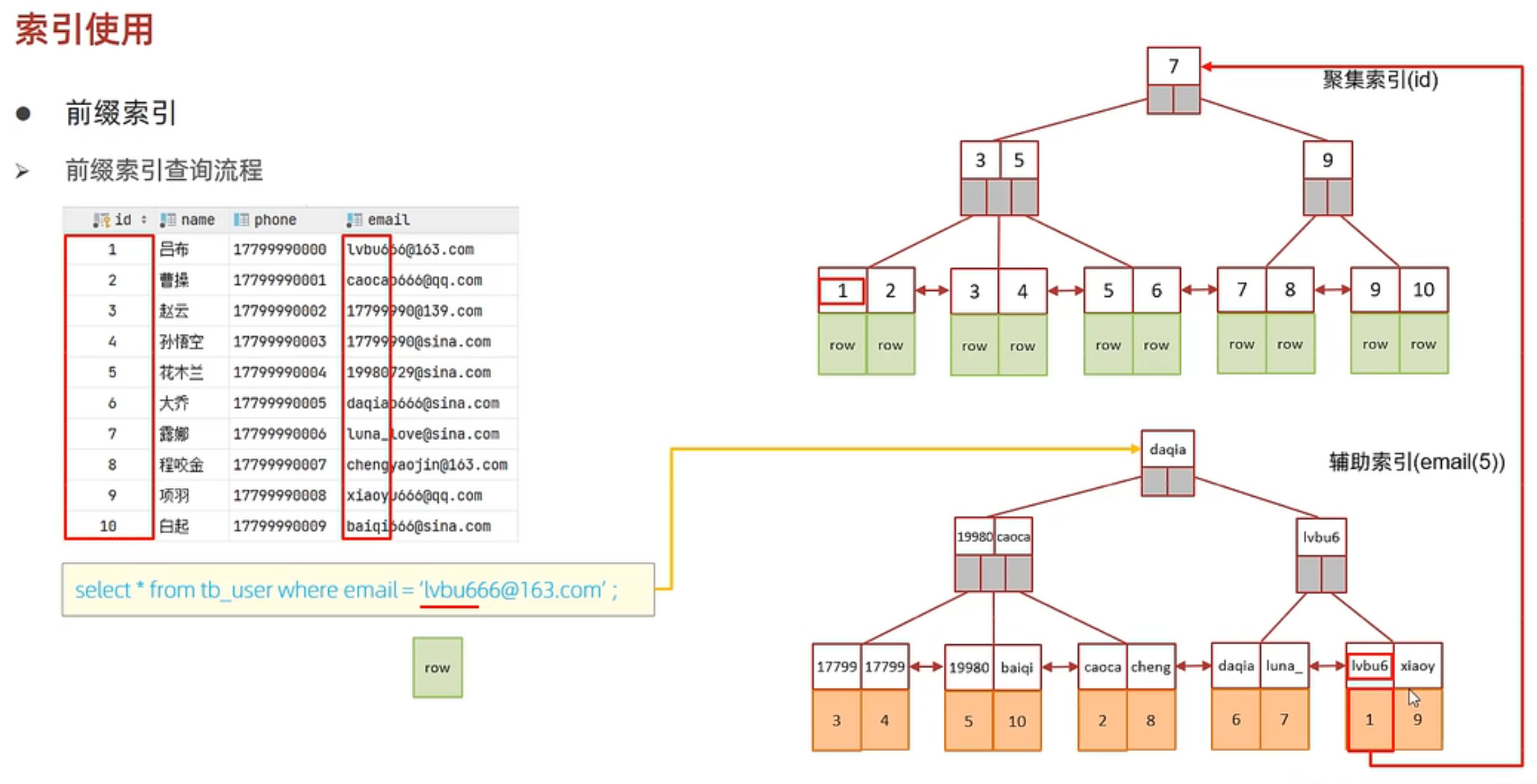
前綴索引:當字段類型為字符串(varchar,text)時,需要很長的字符串,這會讓索引變得很大,查詢時,浪費大量磁盤IO,影響效率。此時可以將字符串的一部分前綴,建立索引,可以大大節約索引空間,從而提高索引效率。根據索引的選擇性來決定,選擇性是指不重複的索引值和數據表的記錄總數的比值,索引選擇性越高,唯一索引的選擇性是1,這是最好的索引選擇性,性能也是最好的。
create index id_xxx on table_name(column(n))
聯合索引:在業務場景中,如果存在多個查詢條件,考慮針對查詢字段建立索引時,建議建立聯合索引。
總結
- 針對數據量較大,且查詢比較頻繁的表建立索引
- 針對常作為查詢條件、排序、分組操作的字段建立索引
- 盡量選擇區分度高的列作為索引,盡量建立唯一索引
- 如果時字符串類型的字段,字段的長度較長,可以針對字段特點建立前綴索引
- 盡量使用聯合索引,減少使用單列索引,查詢時可以覆蓋索引,節省存儲空間,避免回表,提高查詢效率
- 控制索引數量,索引越多,維護索引的代價越大,影線增刪改的效率
- 如果索引不能儲存 NULL,請在建表時使用 NOT NULL 約束它。優化器知道每列是否包含 NULL 值時,它可以更好確定哪個索引最有效地用於查詢